大模型训练需要数据至多,参数量之大,计算时间之巨难以想象,这导致深度学习进入分布式时代,没有单台或者单颗GPU能在满足的时限内完成训练,故分布式成为了大模型从业人员的基础。
大模型并行分为:
- 数据并行: 每个计算设备都有一份模型,将数据分批给不同的计算设备。
- 模型并行: 每个计算设备都有一份数据,将模型分批给不同的计算设备。
- 流水线并行: 流水线并行将模型的各个层分布在不同的计算设备中,使前后阶段可以流水式、分批的进行工作。
- 张量并行: 根据模型的具体结构和算子类型,将某一个算子的计算切分到不同设备,需要保证数学的前后一致性问题。
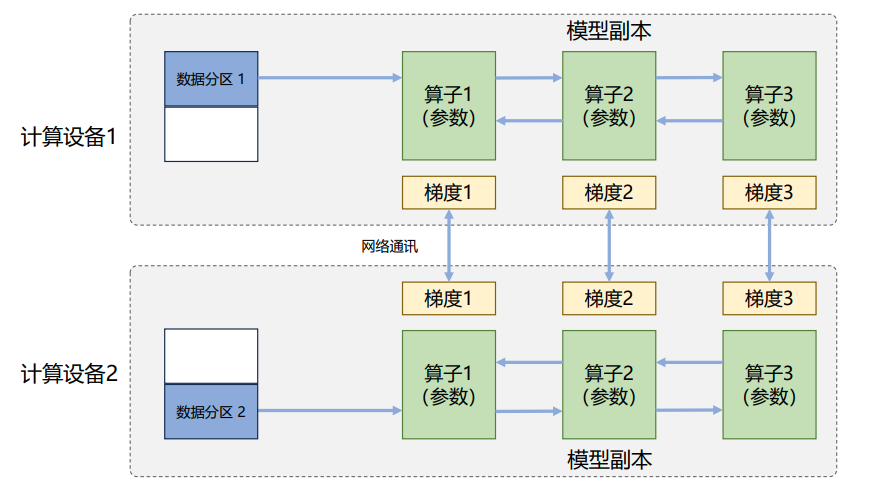
1 数据并行
每个计算设备都有一份模型,将数据分批给不同的计算设备。
2 模型并行
每个计算设备都有一份数据,将模型分批给不同的计算设备。
2.1 流水线并行
流水线并行包括前向计算和后向计算。
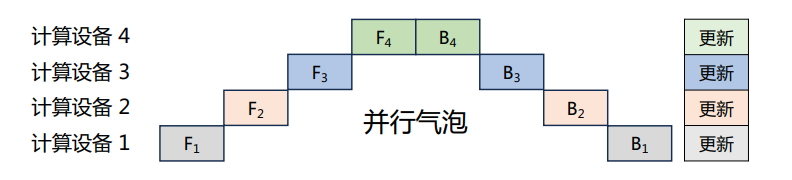
Batch-流水线并行:
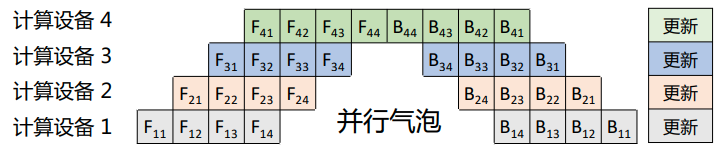
Mini-Batch 流水线并行:
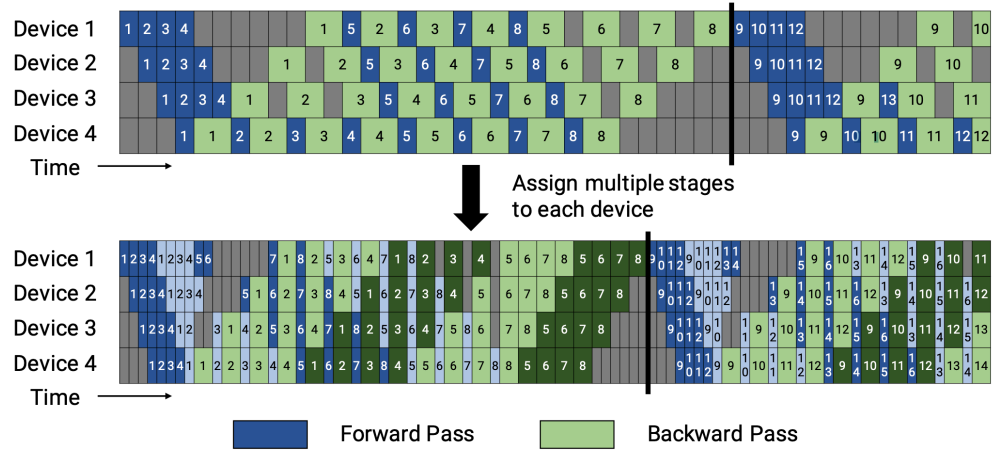
1F1B非交错式流水线并行:
2.2 张量并行
根据模型的具体结构和算子类型,将某一个算子的计算切分到不同设备,需要保证数学的前后一致性问题。
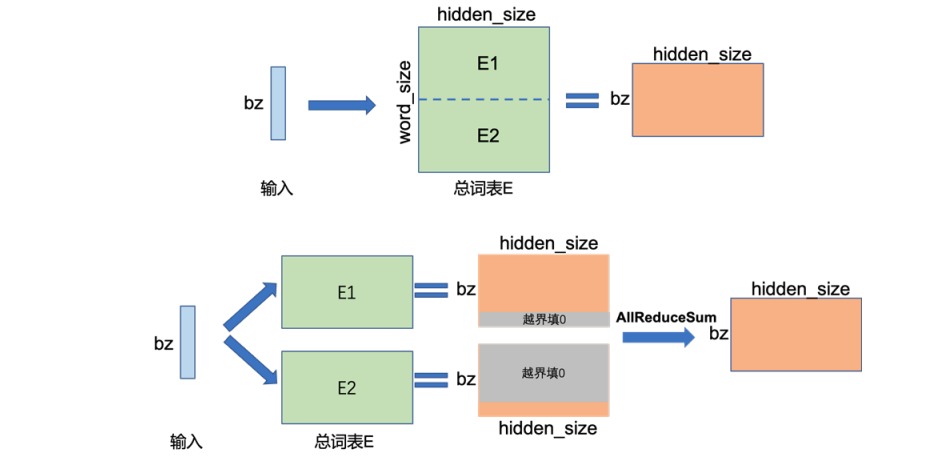
嵌入层:
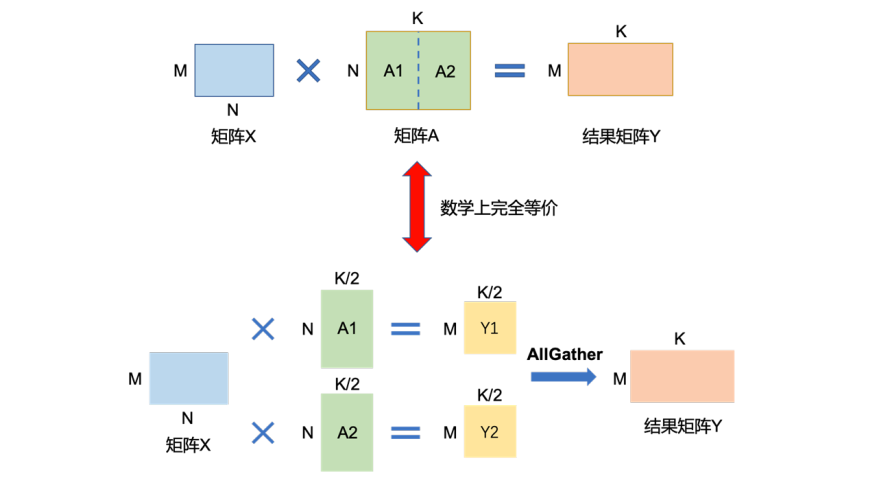
矩阵乘法:
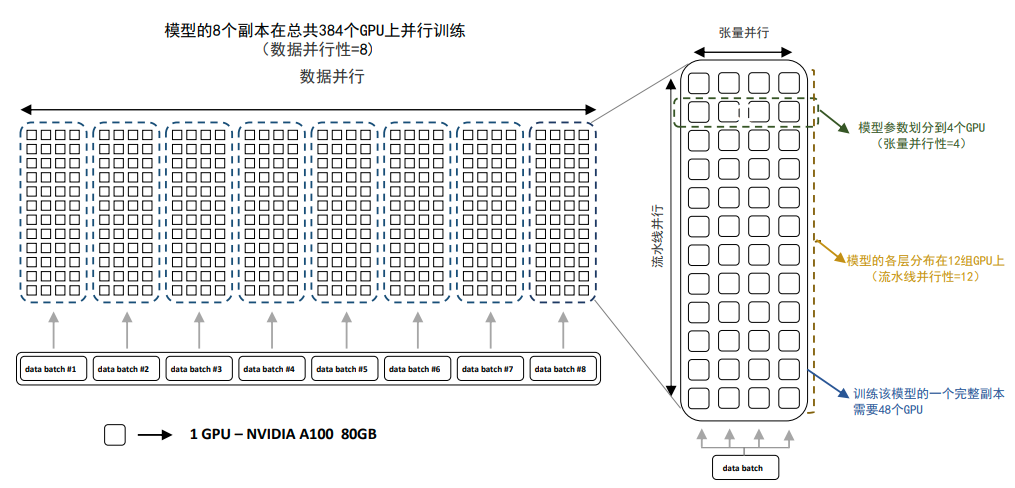
2.3 混合并行
3 内存优化和加速
- 内存优化:该部分工作具体为ZeRO优化器,具体可以看:DeepSpeed – 入门
- 加速:该部分工作具体为AMP混合加速,具体可以看:AMP原理 – 自动混合精度