Deepspeed以其良好的实用性和易用性迅速成为大模型训练和推理的常用框架。
 DeepSpeed不同ZeRO优化器的模式下显存占用情况:
DeepSpeed不同ZeRO优化器的模式下显存占用情况:
 上图的具体细节:
上图的具体细节:

1 DeepSpeed简介
DeepSpeed最让人熟知的就是大名鼎鼎的ZoRO优化器:- ZeRO-0 :不做任何优化
- ZeRO-1:将优化器的参数进行分布式摊分
- ZeRO-2:将梯度参数进行分布式摊分
- ZeRO-3:将模型参数进行分布式摊分
- ZeRo-Offload:将GPU显存转移到CPU和NVME硬盘。
DeepSpeed不同ZeRO优化器的模式下显存占用情况:
- Parameters : 2 | Gradients: 2 | Optimizer States: K = 12(32bit Gradients, 32bit variance and momentum).
上图的具体细节:
2 DeepSpeed前向/反向传播/参数更新
此章节我们查看DeepSpeed如何做模型和数据并行。2.1 前向传播
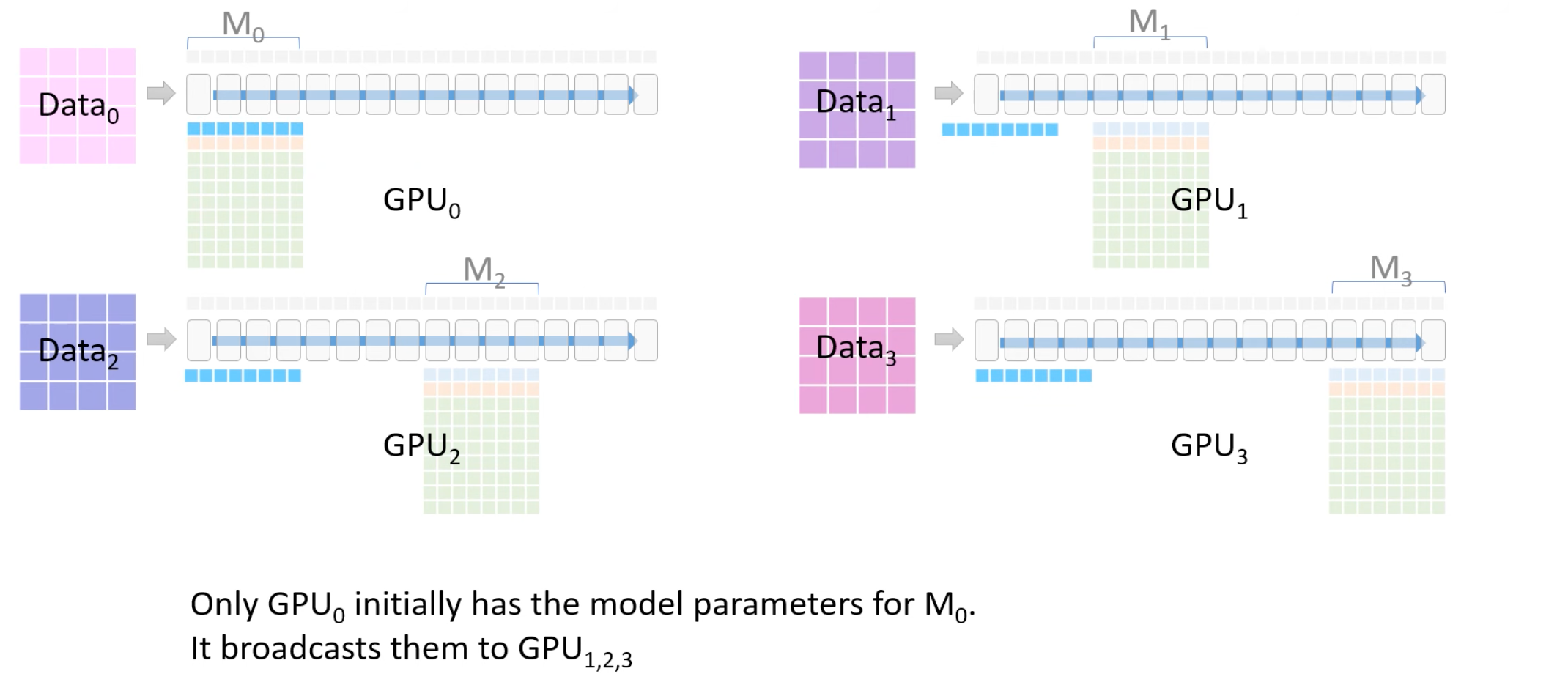
计算每一个GPU持有部分模型的中间激活值。 需要保证每个GPU同时只持有一份数据和最多2部分的模型参数(一份自己持有,另一份广播接收)。- Total:首先每个GPU拿各自的数据Data_i,同时一个model被拆分为4份,每个GPU只计算对应的层。
- 1 GPU0将M0的参数广播到GPU1-2-3中。
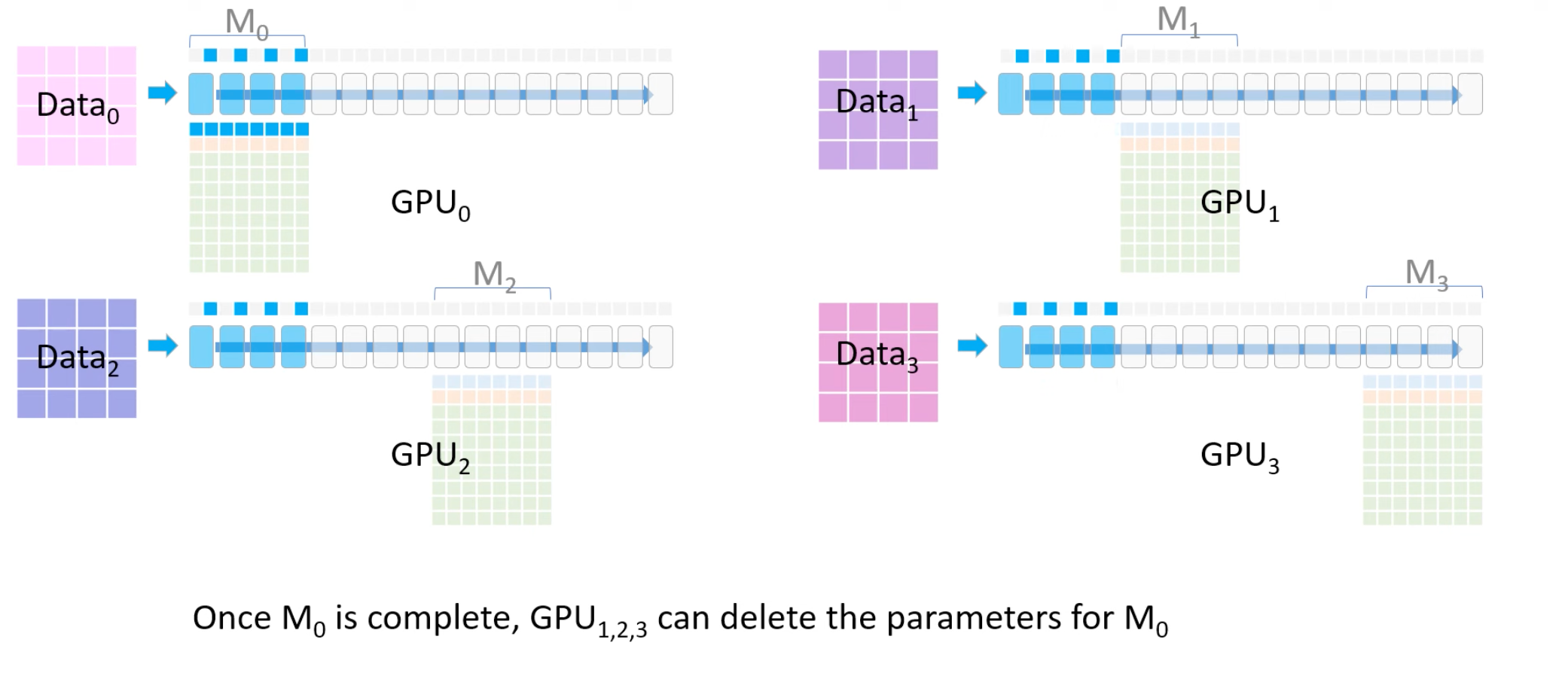
- 2 GPU0-3使用M0参数计算
- 3 GPU1-2-3删除M0参数
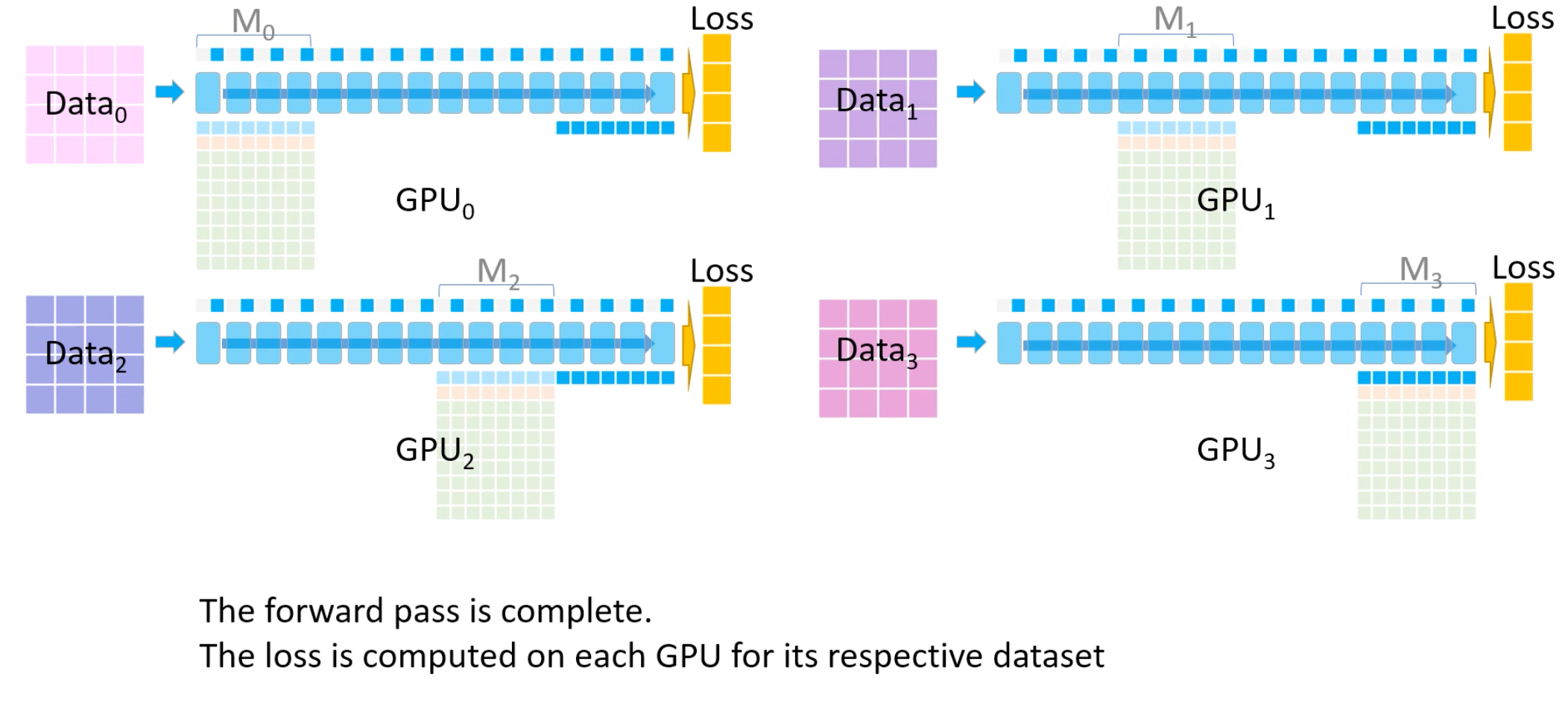
- 4 同理,遇到M1参数计算时,GPU1将M1参数广播到GPU0-2-3配合各自数据进行计算,计算完成之后GPU0-2-3删除M1参数。
- 5 直至前向传播完成,计算得到loss。
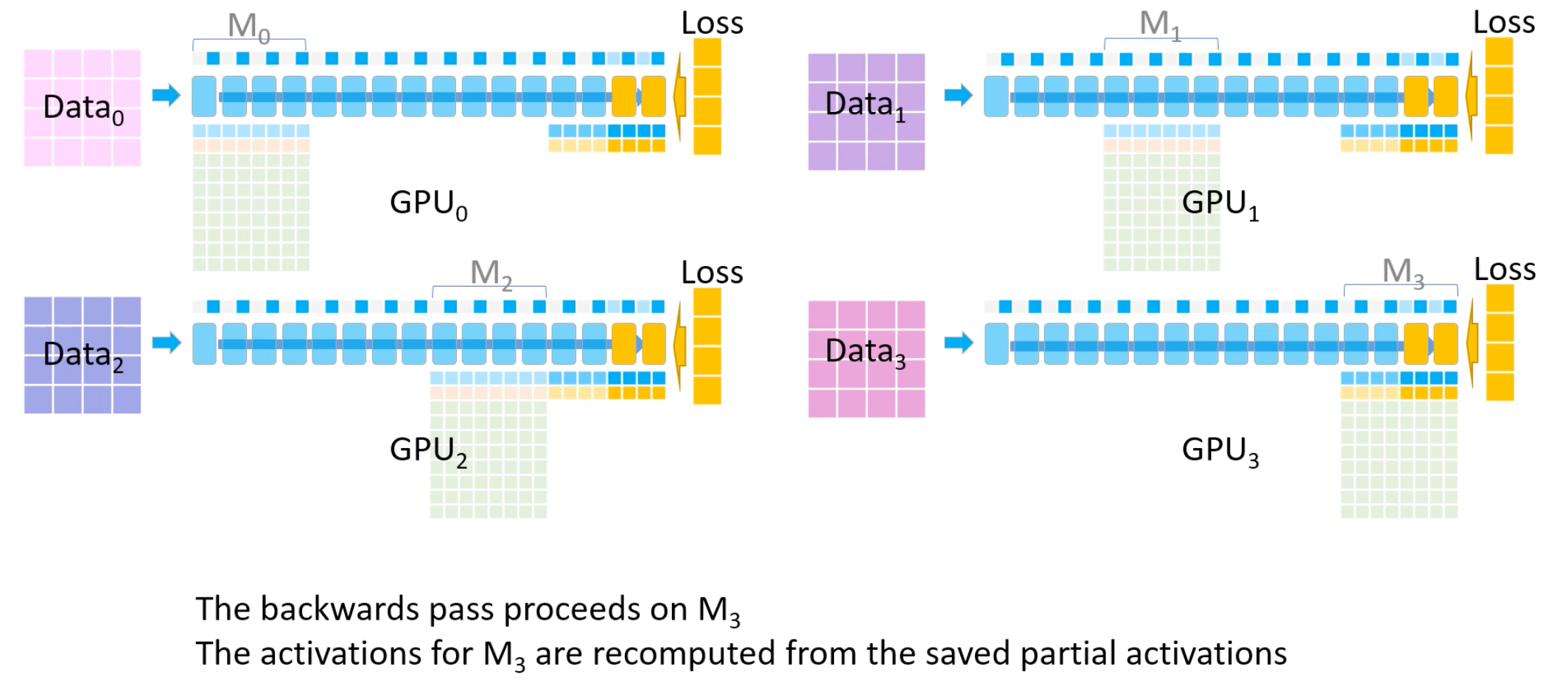
2.2 反向传播
计算每一个GPU持有部分模型的梯度。 需要保证每个GPU同时只持有一份数据和最多2部分的模型梯度(一份自己持有,另一份广播接收)。- Total:首先每个GPU拿各自的数据Data_i,同时一个model被拆分为4份,每个GPU只计算对应的层。
- 1 GPU3向GPU0-1-2进行M3参数的广播。
- 2 GPU0-1-2拿到M3的参数后进行反向梯度的计算。
- 3 GPU0-1-2将计算的到的梯度返回给GPU3后累加得到反向总梯度。
- 4 GPU0-1-2删除M3参数。
- 5 循环1-4的过程,直至计算完成。
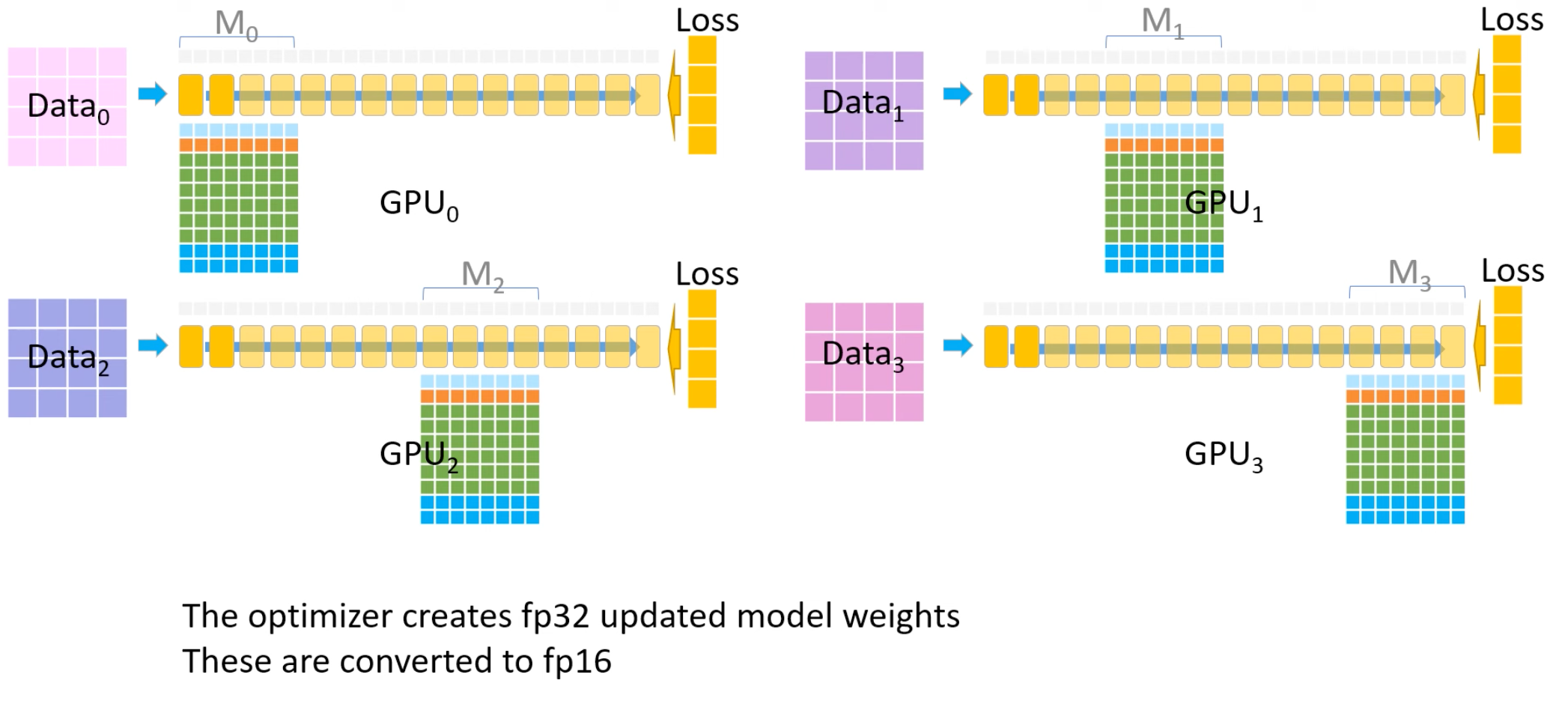
2.3 参数更新
根据每一个GPU持有部分模型的中间值和梯度计算优化器的一阶矩和二阶矩用于参数更新。 需要保证每个GPU同时只持有一份数据和最多2部分的模型参数和梯度(一份自己持有,另一份广播接收)。- Total:首先每个GPU拿各自的数据Data_i,同时一个model被拆分为4份,每个GPU只计算对应的层。
- 1 经过模型的反向传播后,GPU0-3各自拥有一份自己的模型参数和梯度。
- 2 GPU0-3计算各自的优化器参数(一阶矩和二阶矩)
- 3 GPU0-3利用优化器参数更新梯度。
- 4 GPU0-3将fp32的模型参数变成fp16后重新赋值给fp16的模型参数。
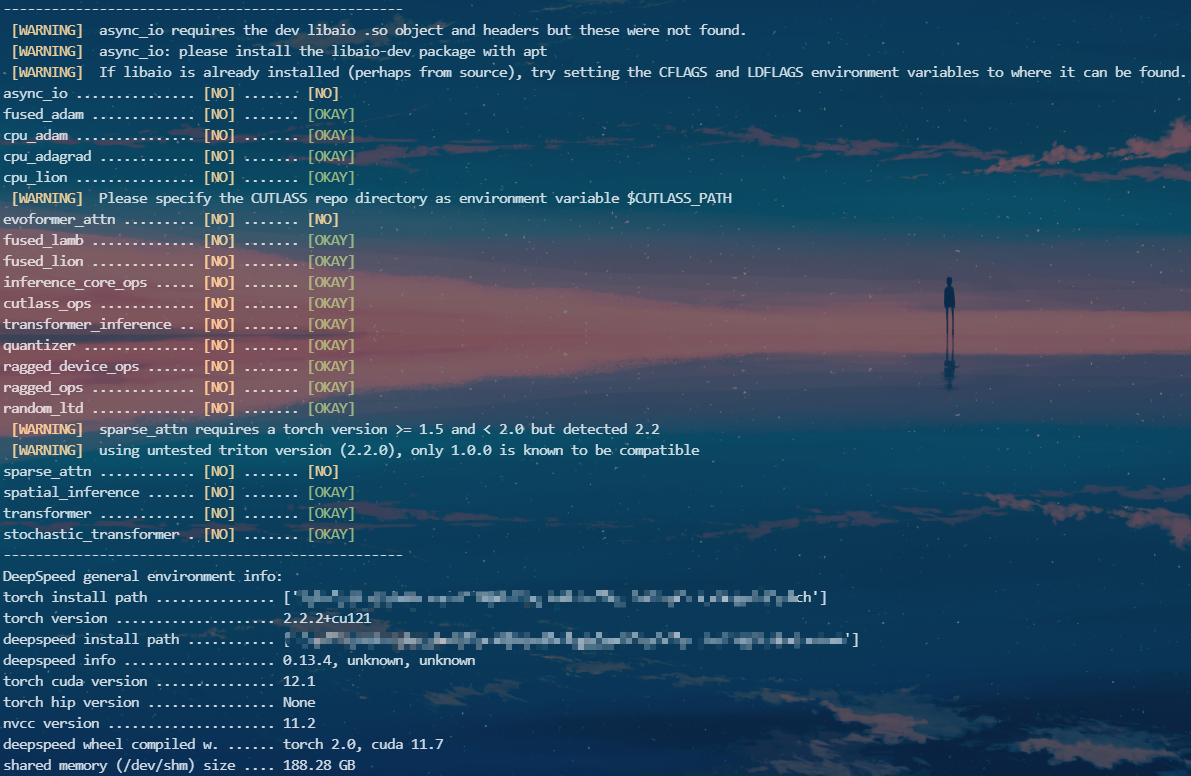
3 DeepSpeed实战演示
此处我们使用transformers库中的examples/pytorch/translation/run_translation.py进行演示,过程中我们会使用ZeRO-1到3来查看显存占用,同时计算一下速度。 启动命令:deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro3.1 ZeRO-1
配置文件如下:3.2 ZeRO-2
配置文件如下:{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}3.3 ZeRO-3
配置文件如下:{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "none",
"pin_memory": true
},
"offload_param": {
"device": "none",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}