AMP – 自动混合精度,大家应该听说过很多次,但是具体这个玩意儿到底是什么东西呢?
1 AMP基本流程
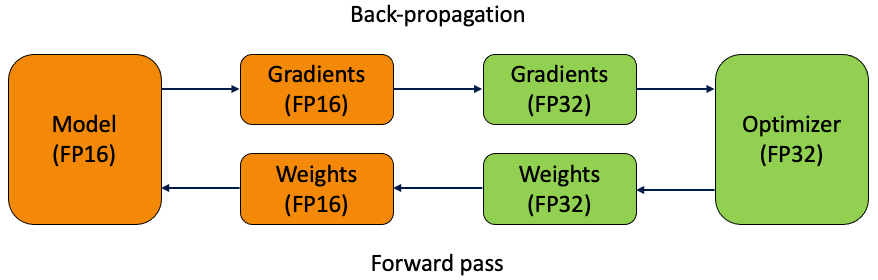
- 1 前向传播中模型参数使用fp16存储
- 2 反向传播中梯度使用fp16存储(为了梯度不下溢(loss太小导致反向传播后梯度下溢),在fp16梯度下使用梯度缩放,计算出loss后,对loss乘以一个很大的数,计算完梯度之后在fp32梯度下除回来恢复原始值。)
- 3 参数更新:由于更新权重=学习率*梯度,导致更新参数非常容易溢出,故先将梯度从fp16转化为fp32,进而计算优化器的参数:一阶矩和二阶矩都使用fp32存储。同时为了更新参数的稳定,模型参数使用备份的fp32版本,计算得到更新后的模型参数后,将其转化为fp16版本参与下一次的前向计算。
2 AMP的loss scale
为了保持反向传播过程中梯度不下溢(loss太小导致反向传播后梯度下溢),在fp16梯度下使用梯度缩放,计算出loss后,对loss乘以一个很大的数,计算完梯度之后在fp32梯度下除回来恢复原始值。
此处有两个版本,针对loss是否使用fp16,一般来说建议loss使用fp32表示。
loss使用fp16: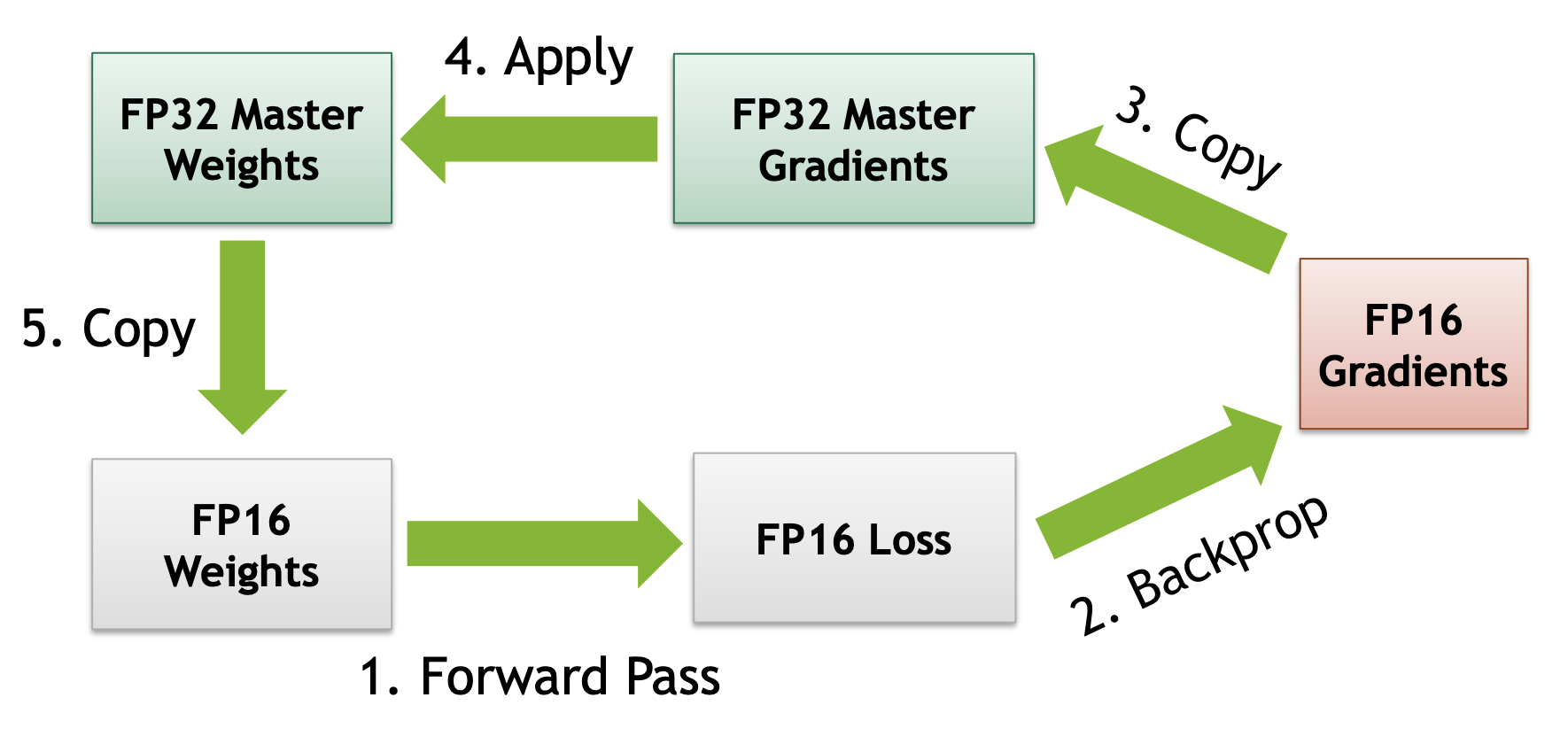
loss使用fp32:
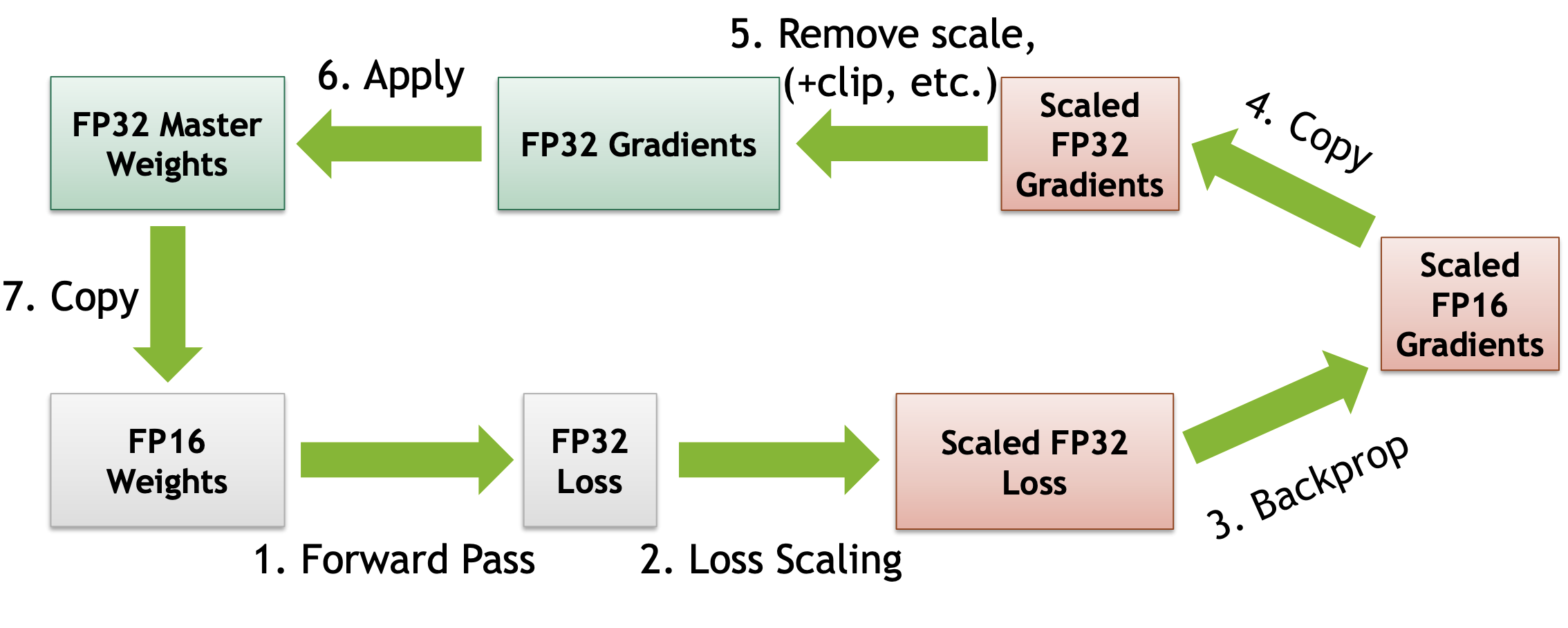
3 AMP的优点
那么为什么要使用AMP呢?节省显存?加速?
- 首先我们来看是否真的节省显存,AMP将前向传播过程的模型参数和反向传播过程的梯度参数使用fp16进行存储,但是为了参数更新时候的稳定时需要备份fp32的模型参数,刚好抵消了前向传播过程中节省的显存,故AMP实际上不节省显存。
- AMP的加速,实际上英伟达GPU在计算fp16和fp32的计算能力是不一致的,fp16的算力会远高于fp32(8X),即前向传播和反向传播都使用fp16进行计算,效率更快;故为了计算效率优先,将fp32转成fp16进行计算能够更加充分的发挥GPU的计算能力。
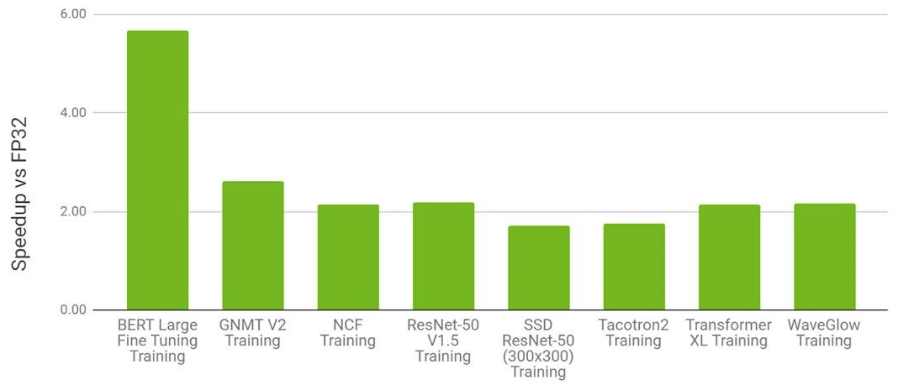
- AMP是否会让性能变差,根据pytorch的官方博客我们看到,基本上不会发生性能的下降。

4 AMP示例
