@减少大模型显存消耗,不过分降低模型性能
目前大模型搞得如火如荼,同时大模型的部署也称为了大家急需关注的问题。大模型如此庞大的参数量,需要大显存的GPU,能不能想一种办法既能减少部署时候的显存消耗,同时不过分降低模型的性能呢。
@大模型量化如何性能不极速下降?
大模型的量化是该问题的答案,模型量化通过线性或者非线性映射将fp32或者fp16映射成为int8,甚至int4,极大的满足了广大AI从业人员对于模型部署的需求。那么,为什么量化可以保证性能不会极速下降呢?
- 1 首先,模型量化过程中的映射确实会导致模型参数分布发生轻微改变,但是由于参数是整体进行映射,故最后模型结果还是会分布在模型新分布可控范围内。
- 2 大语言模型对于文本生成,本质上还是在做分类任务,而分类任务本身具备一定的鲁棒性,只需要该词的概率最大 即可,不像回归任务那么敏感。
- 3 量化引入的误差实际上是可控的,可以使用QAT(量化感知训练)等技术来主动引入量化误差来使模型适应量化误差,从而减少量化误差。
@大模型量化是否可以加速推理?
这时候又有新的从业人员发表意见,既然大模型可以从fp16量化为int8,同时英伟达显卡对int8的计算效率比fp16高,那么量化是否可以加速推理?
- 1 结论是不一定,甚至量化后模型推理会更慢。
- 2 量化模型推理过程中涉及大量的量化和反量化步骤,拖慢了推理性能。
- 2.1 由于量化为int8之后,int8的范围太小,在计算过程中很容易产生溢出,故需要使用fp32存储中间值激活值。
- 2.2 fp32激活值需要先量化为int8后与量化模型参数进行计算,计算结果使用INT32存储,之后将INT3反量化为fp32作为中间激活值。
餐前小菜已经吃完了,我们步入正题,我们分别用量化是否线性、量化粒度、量化方法三大分类标准入手探讨。
1 量化是否线性
1.1 线性映射
线性映射是指映射过程中的映射函数是线性的。
同时线性映射也被分为对称映射和非对称映射。
- 对称映射:量化前后的数值都是以 0 为中点对称分布。
- 非对称映射:relu等激活函数会导致数值的分布不是以0对称。
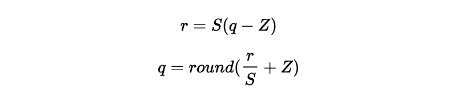
 非对称映射的例子:
非对称映射的例子:

1.2 非线性映射
线性映射没有考虑原始数据的分布,例如正态分布,越靠近0数据分布越密。量化后的数值也会集中在0附近,导致极端情况下大批数据变成0.
故我们希望给稠密分布的区域给更多的分布映射,即最后量化后的空间变成均匀分布。
- 1 分位量化方法:寻找一些分位点为原数据进行划分,使各个区间的数据个数相等,然后将同一个区间内的数据映射成同一个值,从而实现量化。
- 2 求分位点方法:先将原始数据归一化到[-1, 1],使用累计分布函数的反函数,通过分布函数的值反求分位点。
例如QLoRA:


2 量化粒度
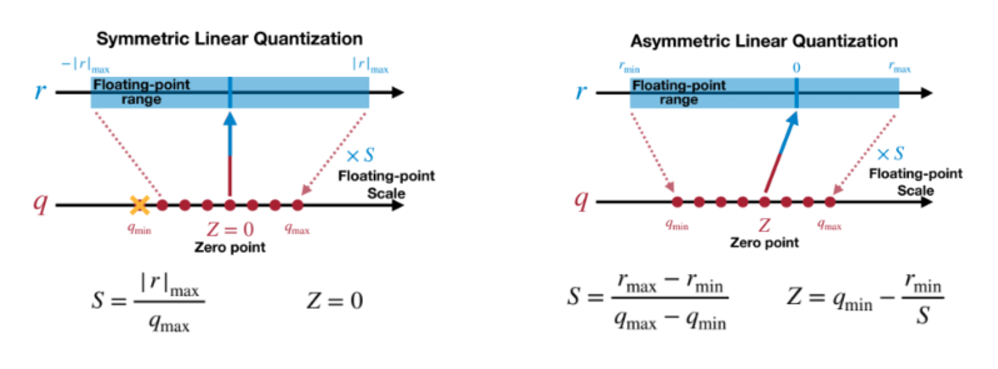
量化粒度是指选取多少个待量化的参数共享量化系数(缩放系数和中点),通常来说粒度越大,精度损失就越大,粒度越小,精度损失就越小,但是需要更多的缩放系数。
3 量化方法
模型量化对象主要集中在权重、激活值、KV Cache。
- 权重:训练完后固定,数值范围与输入无关,可以离线完成量化。
- 激活值:激活输出随着输入变化而变化,需要统计数据的动态范围(缩放系数),范围统计的时机有两种:
- 训练时统计
- 在推理过程中使用小批量数据进行统计
我们将量化方法分为两类:
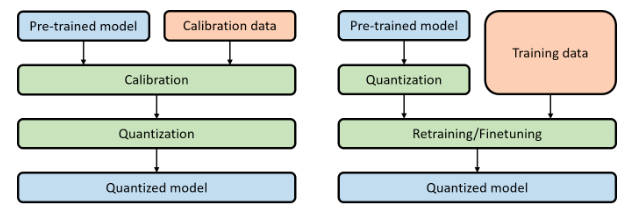
- 1 训练后量化 – PTQ
- 2 量化感知训练 – QAT
3.1 PTQ
训练后量化,简单高效,只需要训练好的模型和少量的校准数据,无需重新训练模型。
* Dynamic PTQ:仅量化权重,激活在推理时量化。
* Static PTQ:权重和激活都量化,需要校准数据。
3.1.1 Danamic PTQ

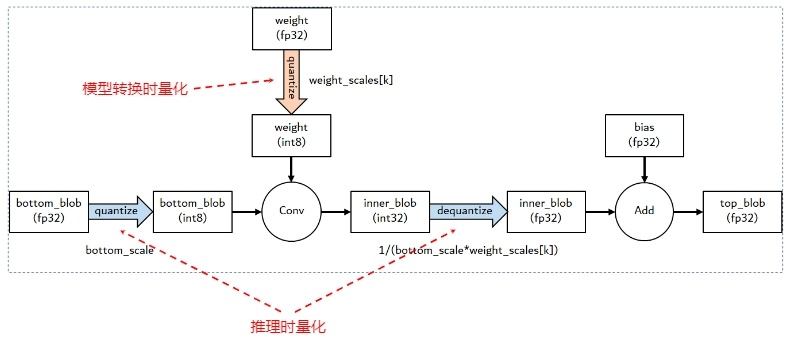

3.1.2 Static PTQ
量化权重和激活值:
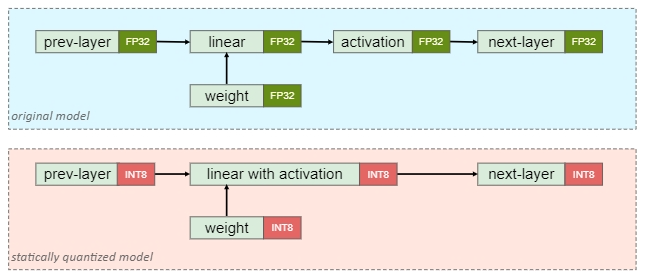
统计激活值范围的常用方法:
- 1 Min-Max
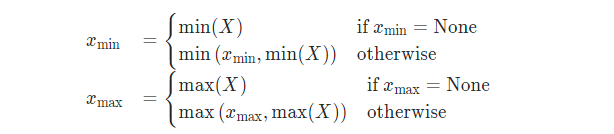
- 2 Moving Average Min-Max
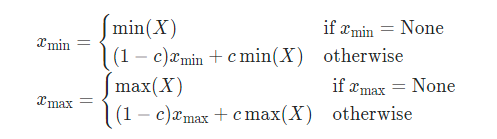
- 3 Histogram
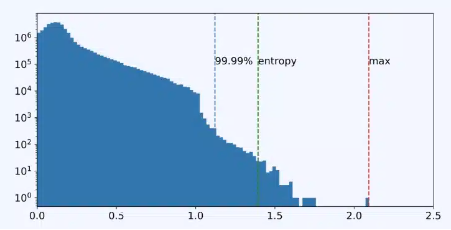
Pytorch:

3.2 QAT
量化感知训练,需要在模型中添加伪量化节点模拟量化,需要重新训练模型。
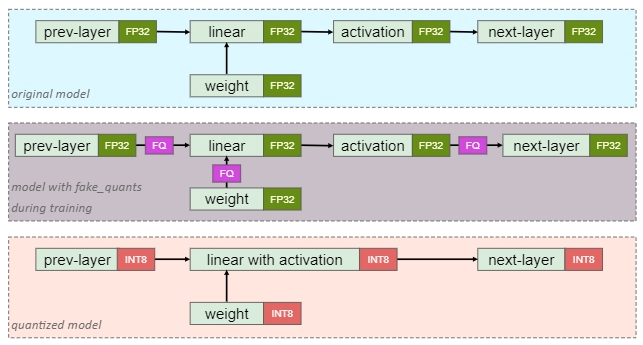
伪量化节点的功能:
- 1 统计数据范围(Min-Max),偏移值Z和Scale
- 2 对输入输出进行模拟量化(依然为FP32),从而让模型感知到量化的影响

伪量化函数的特点:
- 1 forward pass:阶梯状函数
- 2 backward pass :直通函数
3.3 PTQ和QAT
4 量化模型
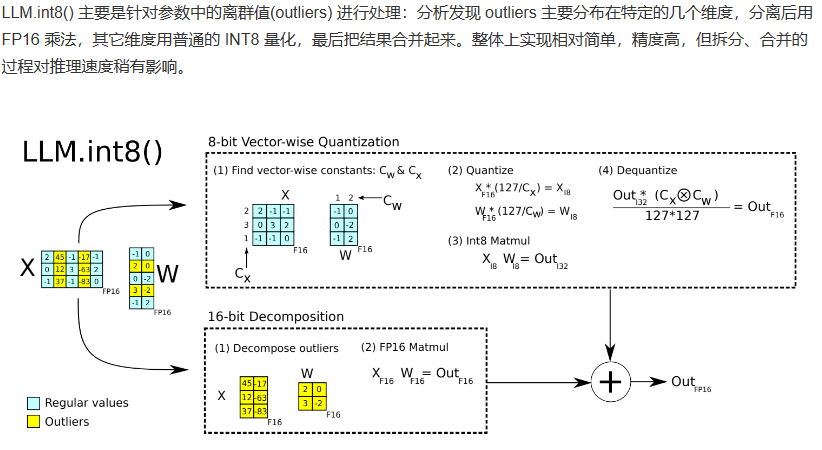
4.1 LLM.int8()
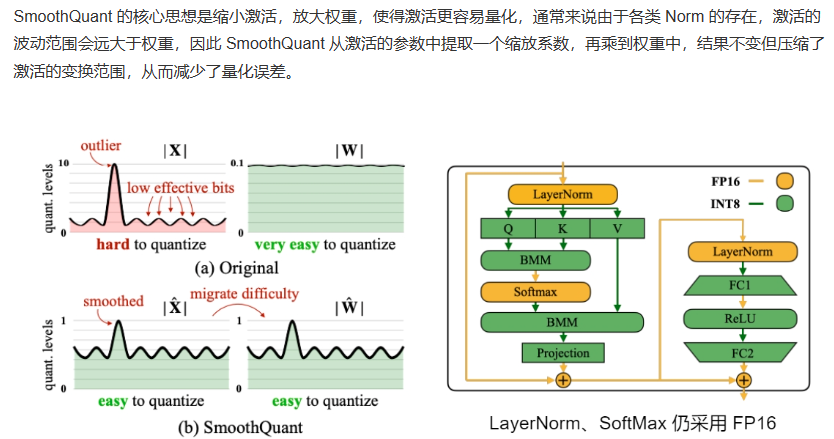
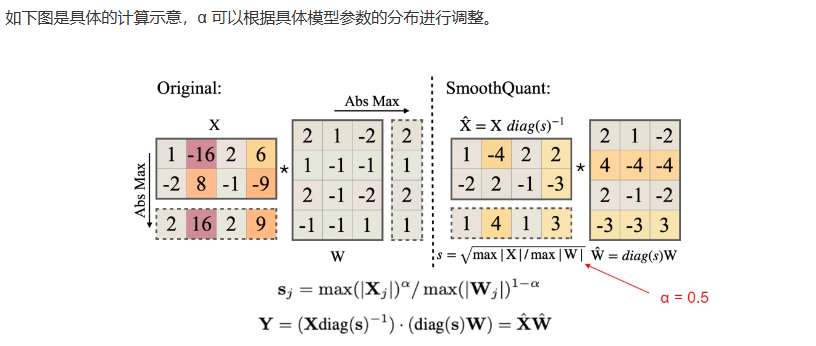
4.2 SmoothQuant
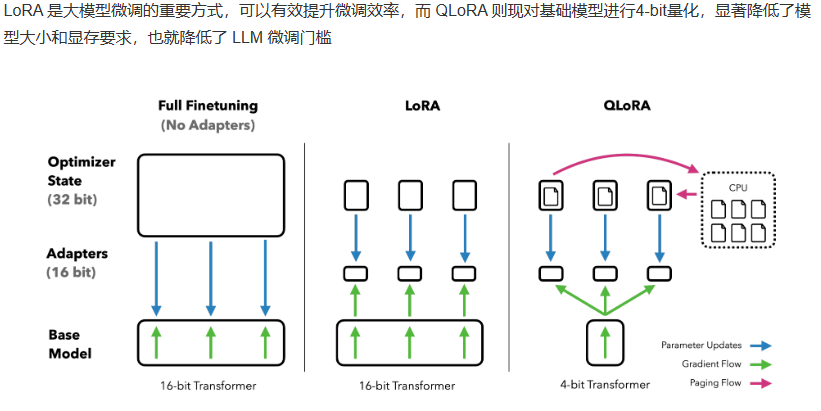
4.3 QLoRA

4.4 GPTQ
