众所周知,LLaVA的框架十分简洁,如下:
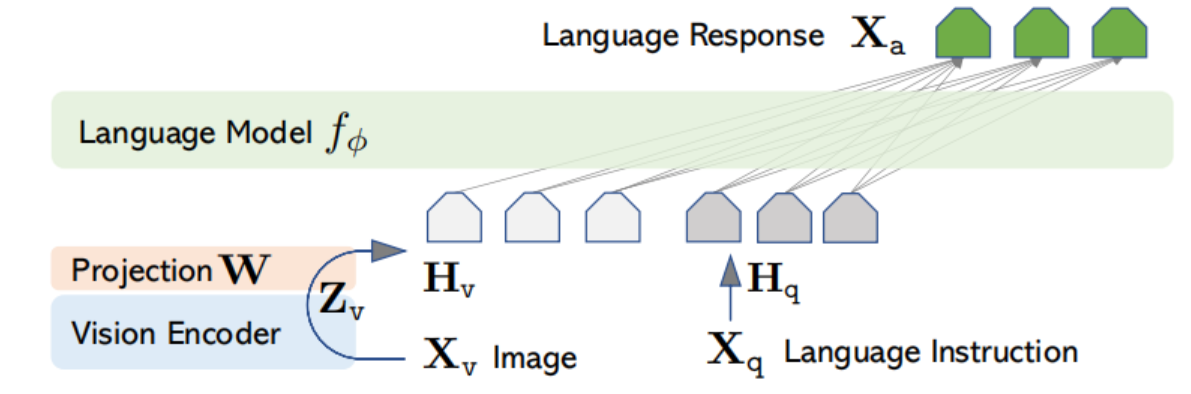
故构建一个对应的vision Encoder和Projection也相对来说比较简单。
1 Projection
vision-text projector是一层或者N层激活函数为gelu的MLP。
- projector_type: linear
- nn.Linear()
- projector_type: mlp2x_gelu()
- nn.Linear()
- nn.gelu()
- nn.Linear()
def build_vision_projector(config, delay_load=False, **kwargs):
projector_type = getattr(config, 'mm_projector_type', 'linear')
if projector_type == 'linear':
return nn.Linear(config.mm_hidden_size, config.hidden_size)
mlp_gelu_match = re.match(r'^mlp(\d+)x_gelu$', projector_type)
if mlp_gelu_match:
mlp_depth = int(mlp_gelu_match.group(1))
modules = [nn.Linear(config.mm_hidden_size, config.hidden_size)]
for _ in range(1, mlp_depth):
modules.append(nn.GELU())
modules.append(nn.Linear(config.hidden_size, config.hidden_size))
return nn.Sequential(*modules)
if projector_type == 'identity':
return IdentityMap()
raise ValueError(f'Unknown projector type: {projector_type}')2 vision Encoder
vision model最重要的是CLIP-VIT Model和CLIP-VIT Processor(切分图片patch)。
- 1 load_model: 设置Model的requires_grad_ = False
- 2 feature_select(): 选择不同的feature,即是否携带cls
- 3 forward(): 切分patch,编码图像。
class CLIPVisionTower(nn.Module):
def __init__(self, vision_tower, args, delay_load=False):
super().__init__()
self.is_loaded = False
self.vision_tower_name = vision_tower
self.select_layer = args.mm_vision_select_layer
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
if not delay_load:
self.load_model()
elif getattr(args, 'unfreeze_mm_vision_tower', False):
self.load_model()
else:
self.cfg_only = CLIPVisionConfig.from_pretrained(self.vision_tower_name)
def load_model(self, device_map=None):
if self.is_loaded:
print('{} is already loaded, `load_model` called again, skipping.'.format(self.vision_tower_name))
return
self.image_processor = CLIPImageProcessor.from_pretrained(self.vision_tower_name)
self.vision_tower = CLIPVisionModel.from_pretrained(self.vision_tower_name, device_map=device_map)
self.vision_tower.requires_grad_(False)
self.is_loaded = True
def feature_select(self, image_forward_outs):
image_features = image_forward_outs.hidden_states[self.select_layer]
if self.select_feature == 'patch':
image_features = image_features[:, 1:]
elif self.select_feature == 'cls_patch':
image_features = image_features
else:
raise ValueError(f'Unexpected select feature: {self.select_feature}')
return image_features
@torch.no_grad()
def forward(self, images):
if type(images) is list:
image_features = []
for image in images:
image_forward_out = self.vision_tower(image.to(device=self.device, dtype=self.dtype).unsqueeze(0), output_hidden_states=True)
image_feature = self.feature_select(image_forward_out).to(image.dtype)
image_features.append(image_feature)
else:
image_forward_outs = self.vision_tower(images.to(device=self.device, dtype=self.dtype), output_hidden_states=True)
image_features = self.feature_select(image_forward_outs).to(images.dtype)
return image_features